¶ Premier projet
Ce projet introductif à l'IA assume que vous êtes comfortable avec les bases de la programmation en Python. Si vous êtes nouveau à la programmation, félicitations! Vous êtes dans le meilleur club pour apprendre, mais voyez avec votre chargé(e) de projet pour voir s'il existe des exercices plus constructif sur les bases de la programmation.
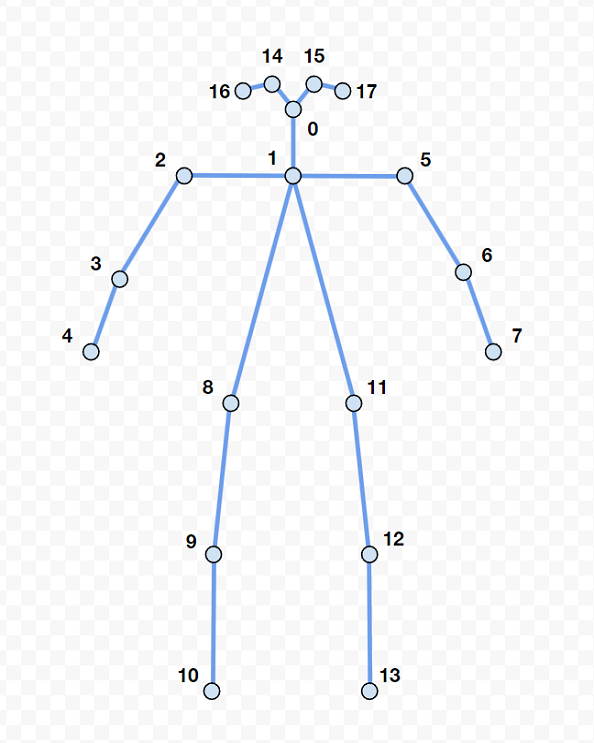
Cette page Wiki se veut un mélange entre un Getting Started et un micro-cours sur l'IA. Pour ce faire, nous reconstruirons le projet de détection de pose. Celui-ci est parmi les premiers efforts du club à intégrer de l'IA dans ses robots, et est réalisable avec un très petit réseau de neurones, nommé un MLP. Pour que la détection de pose soit utile dans le contexte d'une compétition, il faut qu'un plus gros modèle, comme un YoloV8, nourrit le MLP avec des squelettes comme montré par la photo ci-dessous:


Le YoloV8 qui s'occupe de générer les squelettes est en fait un modèle offert par la caméra ZED. Conséquemment, il en faut une pour reproduire ces beaux résultats. Si vous êtes au local du club et que par chance une des ZED et un des Jetson n'est pas installée sur le robot, vous pouvez essayer de faire rouler le code détection de pose.
Pour garder les choses simples, nous allons nous concentrer uniquement sur le MLP qui détecte les poses à partir des squelettes. Heureusement, celui-ci est extrêmement petit (3232 neurones officiellement, mais il peut être rendu plus petit encore) et peut être entraîné facilement sur n'importe quel ordinateur. Nous verrons aussi qu'une grande partie du développement d'intelligence artificielle est en fait du traitement de données.
Ce tutoriel offre beaucoup de code pré-écrit et permet à quelqu'un sans expérience d'obtenir des résultats rapidement. Si vous désirez apprendre en détail le fonctionnement d'un réseau de neurone et tout le traitement de données qui l'entoure, c'est votre responsabilité de rejeter le code pré-écrit et de vous salir les mains en reproduisant les résultats de prédiction de pose grâce à votre propre code.
¶ 1. Créer son environnement de développement
Lors du développement d'une intelligence artificielle en Python, il est essentiel de travailler dans un environnement bien configuré. L'utilisation d'un environnement virtuel (venv) permet d'isoler les dépendances de votre projet pour éviter les conflits entre différents projets ou avec les bibliothèques globales. En théorie, si vous suivez ce tutoriel, vous devriez être déjà à l'aise avec la création d'un espace de travail en Python dans un IDE de votre choix. Conséquemment, la plupart des étapes devraient être triviales. L'essentiel à retenir c'est l'environnement virtuel (venv) dans lequel nous allons installer toutes nos libraires.
ChatGPT ou Claude seront excellent à vous débloquer si certaines étapes ne se déroulent pas comme prévu. Vous pouvez vous fier sur les buts de chaque étape pour guider les LLM.
- Télécharger Python
But: Installer la version plus récente de Python en s'assurant d'avoir pip et venv.
Pour commencer, téléchargez Python à partir du site officiel (python.org/downloads) et installez-le. Lors de l'installation, cochez l'option "Add Python to PATH" avant de continuer. Une fois l'installation terminée, ouvrez un terminal et vérifiez que Python et son gestionnaire de paquets pip sont correctement installés en exécutant les commandes suivantes :
python --version
pip --version
- Télécharger VSCode (si vous ne l'avez pas déjà)
But: Installer VSCode et les extensions Python (de Microsoft) et Pylance.
Vous pouvez ignorer cette étape si vous utilisez un autre IDE.
Installez Visual Studio Code. Une fois installé, cherchez sur Google comment ajouter l'extension Python (de Microsoft) et Pylance pour une expérience optimale (je sais que c'est poche quand un tuto vous demande de chercher sur Google, mais je promet que c'est facile). Une fois les extensions installées, redémarrez VSCode.
- Créer un environnement de travail
But: Créer un dossier de travail dans votre ordinateur puis l'ouvrir dans votre IDE. Créer ensuite un environnement virtuel Python avec les librairies Numpy, Torch, Scikit-Learn, Pandas, Matplotlib et Seaborn.
Créez un dossier sur votre machine pour votre projet, par exemple :
Documents/
└── PoseDetection/
Ouvrez ce dossier dans VSCode via File > Open Folder.
Depuis le terminal intégré de VSCode (voir comment ouvrir un Terminal dans VSCode sur Google), créez un environnement virtuel dans la racine de votre dossier en exécutant la commande suivante :
python -m venv venv
Cette commande génère un dossier venv contenant les fichiers nécessaires à l'environnement virtuel. Vous devriez maintenant voir un nouveau dossier nommé venv dans la barre de navigation de projet de votre IDE.
Documents/
└── PoseDetection/
├── venv/
Activez cet environnement avec l'une des commandes suivantes, selon votre système d'exploitation :
- Windows:
venv\Scripts\activate - macOS/Linux:
source venv/bin/activate
Une fois activé, le nom de l'environnement (venv) s'affichera au début de la ligne de commande. Ceci veut dire que toutes librairies que nous installerons via la ligne de commande sera stockée dans l'environnement virtuel et non globalement.
Installez les librairies que nous aurons besoin avec la commande suivante dans le terminal:
pip install numpy torch scikit-learn seaborn pandas matplotlib
L'installation devrait se faire automatiquement une fois la commande lancée.
¶ 2. Télécharger l'ensemble de données
L'ensemble de données que nous utiliserons a été construit par Capra pour ce projet. Il nous permet d'entraîner un réseau de neurones à détecter les 4 poses suivantes (à partir de squelettes):
- T-pose (Bras parallèle au sol)
- Skyward (Bras droit vers le ciel)
- Bucket (Coudes à 90 degrés avec les avant bras vers le ciel)
- Aucune pose
Vous pouvez le télécharger ici.
L'ensemble de données est en fait un amalgame de fichiers .json qui contiennent chacun des captures d'une caméra ZED. Le titre des fichiers dicte la pose qui est représentée par les captures. Une capture est un instant dans le temps, représenté par un chiffre (timestamp), et chaque capture possède un objet Bodies. L'objet Bodies contient une liste de BodyData. Les objet BodyData représentent les détections d'humains dans l'image (une par humain). C'est à l'intérieur de cet objet BodyData que nous trouverons les squelettes. En effet, l'attribut "keypoint" contient, dans notre cas, 18 points en 3 dimensions qui représentent chacun une articulation du squelette. Puisque les poses que nous voulons détecter sont effectuées uniquement par les bras, nous allons utiliser que les points [ 4, 3, 2, 1, 5, 6, 7 ].
Alors qu'on peut penser que l'IA se compose principalement de travaux d'architecture et de construction de réseaux de neurones, la réalité c'est que la majorité du travail est en fait du traitement de données. Dans notre cas, la données est très mal stockée: c'est horrible de garder plusieurs fichiers .json distincts pour une même pose, et il faut faire beaucoup d'effort pour extraire les squelettes. Si vous vous sentez aventurier, se serait une excellente contribution pour le club de faire une V2 de l'ensemble de données, où l'on a en fait un seul fichier .json organisé de la manière suivante (ChatGPT peut facilement vous aider avec ça):
{
"poses": [
{
"id": 1,
"keypoints": [
// ... Les keypoints 3D
],
"label": "bucket"
},
{
"id": 2,
"keypoints": [
// ... Les keypoints 3D
],
"label": "none"
}
// ... Toutes les autres poses
]
}
Bref, revenons à nos moutons. Après avoir téléchargé l'ensemble de données, décompressez au besoin et déposez le à la racine du dossier que vous avez créé à la section 1:
Documents/
└── PoseDetection/
├── venv/
├── dataset/
├── bucket1.json
├── bucket2.json
├── bucket3.json
└── ...
¶ 3. Transformer l'ensemble de données
Une fois que nous avons l'ensemble de données dans notre espace de travail, il faut écrire le code qui va nous permettre de transformer la donnée en objets qui sont compréhensibles par un réseau de neurones. En fait, nous voulons transformer notre données en paires {X, y}, où X est un vecteur de 7x3 dimensions, et y est la réponse (nommé l'étiquette) que le réseau de neurone doit déduire à partir du vecteur d'entrée.
Considérant que notre ensemble de données est très mal formatté et que de le traiter représente une tâche longue et désagréable, vous pouvez télécharger les fichiers json_extractor.py, data.py, constants.py et traces.py. Ensemble, ces fichiers vous permettrons de transformer la donnée en numpy array X et y. Puisque l'ordre est conservé entre les array (élément X1 est lié à l'élément y1), nous allons pouvoir les donner au réseau de neurones et il s'occupera de décomposer le tout en paires. Organisez les comme suit (l'ordre n'est pas important):
Documents/
└── PoseDetection/
├── venv/
├── dataset/
├── tools/
│ ├── json_extractor.py
│ ├── data.py
│ ├── traces.py
└── constants.py
Maintenant que nous avons les méthodes nécessaires pour traiter l'ensemble de données, nous pouvons commencer à coder notre script d'entraînement. Commencez par créer un nouveau fichier Python à la racine du projet nommé train.py.
Documents/
└── PoseDetection/
├── venv/
├── dataset/
├── tools/
│ ├── json_extractor.py
│ ├── data.py
│ ├── traces.py
├── train.py
└── constants.py
Au début du nouveau fichier, insérez les imports suivants:
import torch
import torch.nn as nn
from tools.json_extractor import process_dataset
from tools.data import convertToOneHot, balanceDataset
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
En desous des import, ajoutez le code suivant:
directory = "dataset/"
pose_dict = {"none": 0, "tpose": 1, "bucket": 2, "skyward": 3}
classes = ["none", "tpose", "bucket", "skyward"]
X, y = process_dataset(directory)
Si l'ensemble de données est ailleurs qu'à la racine du projet (ou qu'il s'appel autre chose que dataset), vous allez devoir modifier la valeur de la variable directory. Notez que les imports ne sont pas tous utilisé encore, c'est normal.
Si vous exécutez le fichier Python en entrant la commande suivante dans le terminal:
python train.py
Il ne devrait rien se passer. Si c'est le cas, félicitations! Nous avons maintenant un ensemble de donnée transformé en numpy array prêt à être digéré par un réseau de neurone... en théorie.
¶ 4. Traiter l'ensemble de données
Comme dit précédemment, beaucoup du développement d'intelligence artificielle passe d'abord par de la science de données. Des données de qualité sont toutes aussi importantes que le réseau de neurones: "garbage in, garbage out". Une caractéristique importante que doit avoir la donnée entrante est quelle doit être balancée. Une donnée balancée est une donnée qui a un nombre presque égale d'exemplaire pour chaque classe.
On appelle les différentes catégories d'un ensemble de données des classes. Dans notre cas, nous avons 4 classes: bucket, skyward, tpose et none.
Pourquoi est-ce important pour un ensemble de données d'être balancé? Car si une classe est dominante par rapport aux autres, le réseau de neurone aura tendance à être "trigger happy" pour cette classe. En d'autres mots, puisqu'il la vu beaucoup plus souvent durant son entraînement, il aura tendance à vouloir prédire plus souvent cette classe en production, ce qui n'est pas une situation désirable.
Prenons par exemple un classifieur qui a comme tâche de déterminer si un produit quelconque sur une ligne d'assemblage à un défaut de manufacture. Si le taux de défaut de l'usine est de 1%, et que l'on entraîne le classifieur sur un ensemble de données qui reflète cette réalité dans la distribution de ses classes (normal=99%, défaut=1%), alors le classifieur pourrait apprendre à prédire systématiquement que tous les produits sont 'normaux', car cela lui permettrait d'atteindre une précision apparente de 99 %. Cependant, ce comportement est problématique, car il ignore complètement la classe minoritaire (les produits défectueux), qui est précisément celle qui doit être détectée.
Regardons si notre ensemble de données est balancé en ajoutant ces lignes de code à notre fichier train.py:
unique, counts = np.unique(y, return_counts=True)
clean_dict = {str(k): int(v) for k, v in zip(unique, counts)}
print("Incoming data:", clean_dict)
Si vous exécutez maintenant le fichier (assurez vous de sauvegarder), vous devriez voir le résultat suivant dans votre terminal:
Incoming data: {'bucket': 1004, 'none': 1952, 'skyward': 1139, 'tpose': 1045}
Ceci nous indique que notre ensemble de données est grandement débalancé, avec beaucoup plus d'exemples pour la classe "none". Une solution trivial à notre problème est de simplement limiter le nombre d'exemples par classe au minimum des 4. Ajoutez le code suivant à la fin du fichier train.py pour balancer l'ensemble de données:
X_balanced, y_balanced = balanceDataset(X, y)
unique, counts = np.unique(y_balanced, return_counts=True)
clean_dict = {str(k): int(v) for k, v in zip(unique, counts)}
print("After balancing:", clean_dict)
En exécutant, vous devriez maintenant voir le résultat suivant dans votre terminal:
After balancing: {'bucket': 1004, 'none': 1004, 'skyward': 1004, 'tpose': 1004}
Notre ensemble de données est maintenant balancé! Il est maintenant temps de le subdiviser en trois parties: un ensemble d'entraînement, un ensemble de validation et un ensemble de test.
Un réseau de neurones est toujours entraîné sur un sous-ensemble des données pour s'assurer qu'il soit évalué sur des exemples qu'il n'a jamais vus auparavant. Pendant l'entraînement, on utilise un ensemble d'entraînement pour ajuster les hyperparamètres et l'ensemble de validation pour surveiller la performance du modèle. Suite à l'entraînement, on évalue la performance final sur l'ensemble de test. C'est l'équivalent d'un étudiant qui s'entraîne avec la matière du cours et les examens formatifs, ajuste ses méthodes d'apprentissage en fonction de ses résultats intermédiaires, puis passe un examen final avec des questions qu'il n'a jamais vues.
L'objectif est de tester la capacité de généralisation du modèle. Si le modèle performe très bien sur l'ensemble d'entraînement mais mal sur l'ensemble de validation, cela peut indiquer un sur-ajustement aux données d'entraînement. Si la performance est bonne sur l'ensemble de validation mais mauvaise sur l'ensemble de test, cela peut signifier que les ajustements faits pendant l'entraînement n'ont pas généralisé à de nouvelles données. Ce phénomène, appelé overfitting, est un problème auquel il faut faire très attention.
Un split standard est dans les environs de 80/10/10. Ajouter ce code à la fin de votre fichier:
# On sépare une première fois pour l'ensemble de test
X_train, X_test, y_train, y_test = train_test_split(
X_balanced, y_balanced, test_size=0.2, random_state=1
)
# On sépare une deuxième fois pour l'ensemble de validation
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.1, random_state=1
)
# On aplati les vecteurs d'entrée pour qu'ils passent de (4016,7,3) à (4016,21)
X_train = X_train.reshape(X_train.shape[0], -1)
X_test = X_test.reshape(X_test.shape[0], -1)
X_val = X_val.reshape(X_val.shape[0], -1)
# On transforme le type pour que la donnée fonctionne avec PyTorch
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
X_val = torch.FloatTensor(X_val)
Nous avons maintenant un sous-ensemble d'entraînement et de test. Plus qu'une étape avant de pouvoir s'attaquer au réseau de neurones!
En ce moment, nos réponses y (étiquettes) sont des mots (des chaînes de caractères). Cependant, les réseaux de neurones ne peuvent pas traiter directement ces mots. Nous devons donc convertir nos réponses en un format numérique. Une méthode populaire et simple pour y parvenir est de transformer nos données en one-hot vectors. Cela consiste à représenter chaque classe par un vecteur où une seule valeur est égale à 1, tandis que toutes les autres sont égales à 0. La longueur de chaque vecteur correspond au nombre total de classes, et chaque position dans le vecteur est associée à une classe spécifique. Par exemple, considérant que nous avons les classes {bucket, skyward, tpose, none}, "bucket" sera représentée par [1, 0, 0, 0], "skyward" par [0, 1, 0, 0], et ainsi de suite. Cette représentation est particulièrement utile pour la classification, car elle encode efficacement l'appartenance à une classe sans introduire de relations arbitraires entre les classes.

Pour convertir nos y en vecteurs one-hot, ajoutez le code suivant:
pose_dict = {"none": 0, "tpose": 1, "bucket": 2, "skyward": 3}
y_train_oh = convertToOneHot(y_train, 4, pose_dict)
y_val_oh = convertToOneHot(y_val, 4, pose_dict)
y_test_oh = convertToOneHot(y_test, 4, pose_dict)
Le réseau de neurones doit donc prédire le bon vecteur one-hot au lieu du mot qui est associé à la classe. Beaucoup plus simple!
¶ 5. Construire le réseau de neurones
Enfin! La partie fun! Comme mentionné précedement, ce projet nécessite un très petit réseau de neurones nommé un MLP, ou multi-layer perceptron. C'est la forme la plus basique d'un réseau de neurones: une couche d'entrée, n couches intermédiaires et une couche de sortie. Le nombre de neurones de la couche d'entrée doit être égale aux nombres de points qui décrivent un exemple de X, soit 7x3=21 neurones. Le nombre de neurones de la couche de sortie doit être égale à la taille de nos vecteurs one-hot, soit 4. Je n'ai pas eu la patience de finir toutes les connexions inter-neurones dans la photo, vous comprenez le principe...
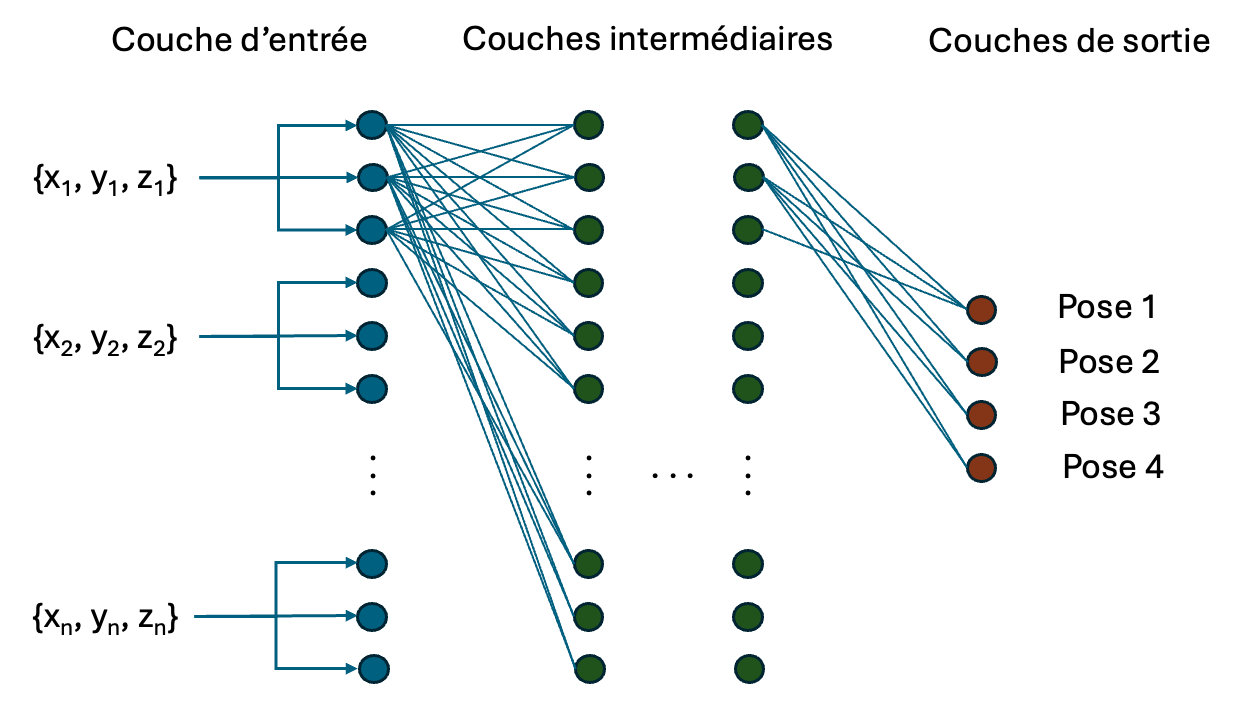
Heureusement, nous n'avons pas à coder une MLP "from scratch". Nous laisserons ceci au cours LOG635 (que je recommande grandement). Au lieu, nous pouvons utiliser la librairie ultra-populaire PyTorch pour très simplement définir l'architecture de notre réseau de neurones et laisser le reste se faire par magie.
Qu'est-ce qu'un réseau de neurone? Cette question peut prendre plusieurs niveaux de difficultés selon le type de réseau que nous étudions. Commençons avec les réseaux les plus simples: les MLP.
Un Multi-Layer Perceptron (MLP) est un type de réseau de neurones artificiels composé de plusieurs couches de neurones entièrement connectées. Il est constitué d'une couche d'entrée, d'une ou plusieurs couches cachées et d'une couche de sortie. Chaque neurone d'une couche est connecté à tous les neurones de la couche suivante, formant ainsi un réseau dense.
Chaque couche est en fait une couche "linéaire" suivie d'une couche "d'activation". La couche linéaire applique une transformation affine sous la forme y = W * x + b où W est une matrice de poids, x le vecteur d'entrée et b un biais. La couche d'activation, quant à elle, applique une fonction non linéaire pour introduire de la non-linéarité et permettre au réseau d'apprendre des relations complexes dans les données.
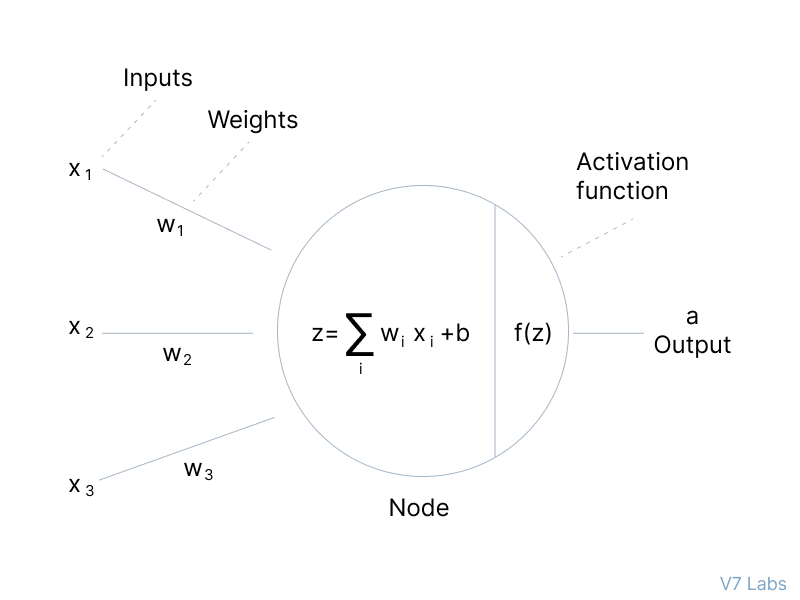
Les couches d'activations sont des fonctions non-linéaires qui simulent l'effet de déclenchement d'un neurone biologique. En d'autres mots, elles offrent aux neurones artificiels la capacité de passer un signal seulement si la somme de tous les signaux entrant est supérieur à un certain seuil. Une fonction d'activation populaire est ReLU:
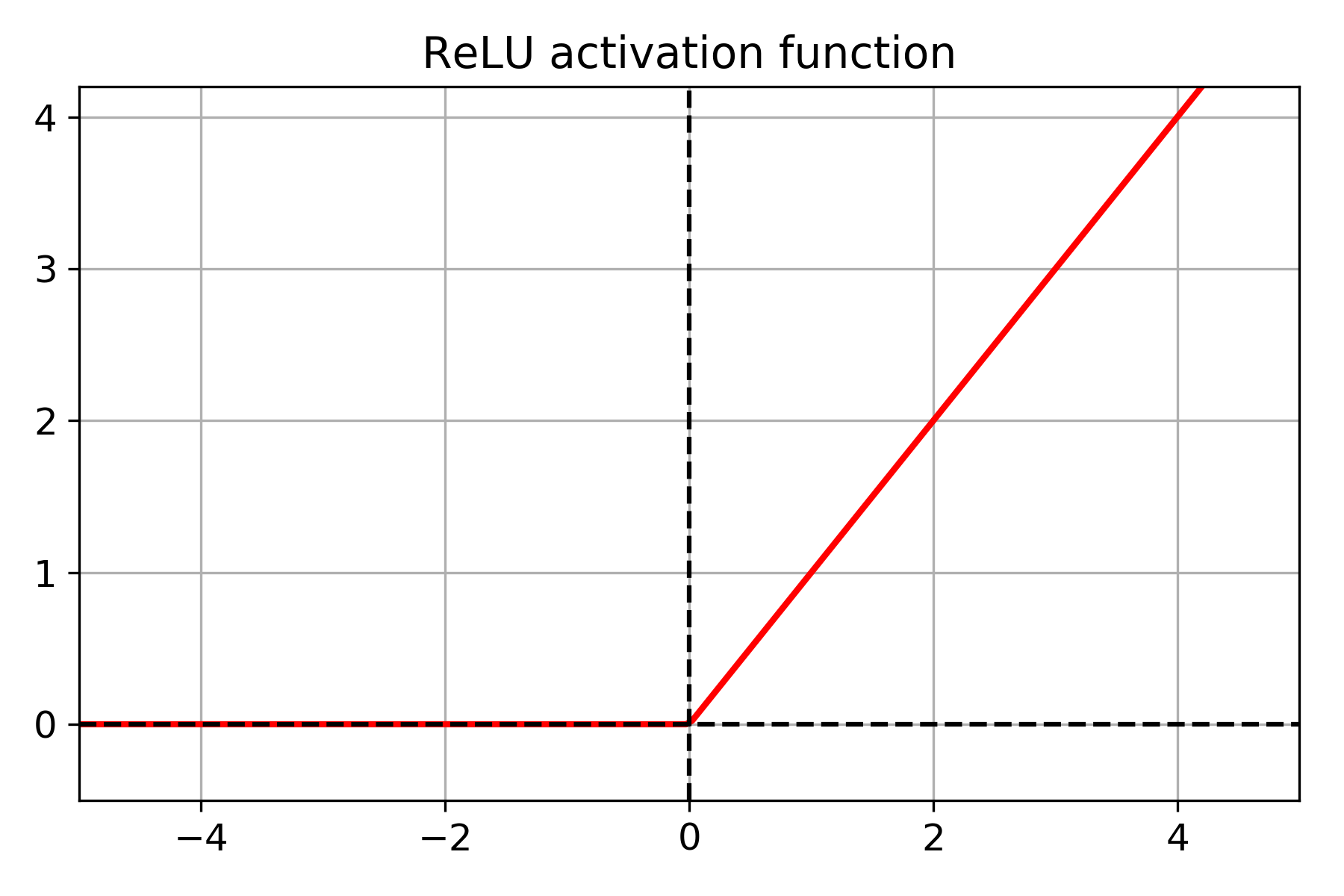
Si cette explication est trop mathématique pour vous, voyez-le ainsi :
Un réseau de neurones fonctionne un peu comme un jeu de filtres successifs. Imaginez que vous essayez de reconnaître un fruit à partir d'une photo. La première transformation (la couche linéaire) extrait des informations brutes, comme la couleur ou la forme, mais ne fait que les réorganiser sans vraiment "comprendre" ce qu'il voit. Ensuite, la couche d’activation agit comme un tri intelligent : elle décide quelles informations sont importantes et lesquelles doivent être ignorées.
C'est comme si vous deviez deviner un mot caché et que chaque couche du réseau éliminait progressivement les mauvaises options pour se rapprocher de la bonne réponse. Sans la couche d’activation, le réseau ne pourrait faire que des combinaisons rigides et ne pourrait pas apprendre des concepts plus abstraits, comme distinguer une pomme d'une poire en fonction de leur texture ou leur éclat.
Bon! Nous allons étendre la classe Module de Pytorch pour construire notre réseau de neurone. Cette classe est grandement utilisée en académie et en industrie puisqu'elle implémente pour nous toute la logique de retropropagation. Tout ce que nous avons à faire, c'est de spécifier les types que couches que nous voulons et comment la donnée passe d'une couche à l'autre; Pytorch se charge du reste. Commençons donc par créer un fichier mlp.py à la racine du projet.
Documents/
└── PoseDetection/
├── venv/
├── dataset/
├── tools/
│ ├── json_extractor.py
│ ├── data.py
│ ├── traces.py
├── train.py
├── mlp.py
└── constants.py
Dans ce fichier, nous devons d'abord importer la librairie nn de Pytorch comme suit:
import torch
import torch.nn as nn
Ensuite nous pouvons définir la classe MLP comme suit:
class MLP(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
Notre classe peut donc faire usage de tous les beaux avantages de la classe Module, ce qui sera très utile pour notre projet. Continuons en initialisant nos couches linéaires et d'activation.
class MLP(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.hidden = nn.Linear(input_size, 32)
self.activation = nn.ReLU()
self.output = nn.Linear(32, output_size)
Qu'avons nous ajouté? À première vu, on remarque qu'il manque une couche d'entrée (on voit seulement hidden et output). La classe nn.Linear désigne en fait une couche de connexions neuronales, soit les paramètres W d'un réseau de neurone. Le nombre des paramètres d'une couche est défini par son nombre de neurone en entrée et le nombre de neurone en sortie. On peut donc voir, dans notre cas, que self.hidden sera une couche de 672 paramètres (21x32). On peut imbriquer plusieurs couches linéaire les unes après les autres autant de fois que l'on veut pour créer un MLP à n couches tant que le nombre de neurones en sortie de la couche n-1 est égale au nombre de neurones en entrée de la couche n. Entre les couches linéaire, nous ajoutons des couches d'activations pour permettre au modèle d'apprendre des fonctions non-linéaires (pas représenté dans la figure ci-dessous).

Nous avons maintenant les couches de notre réseau de neurone. Il reste à spécifier comment la donnée voyage au travers de ces couches. Ceci est fait en implémentant la méthode forward de Module. Dans notre cas, nous prenons comme paramètre de fonction une donnée x (un vecteur), et celle-ci passe d'une couche à l'autre pour devenir la prédiction du modèle. À noter qu'il ne faut pas appliquer d'activation à la dernière couche d'un réseau de neurone.
class MLP(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.hidden = nn.Linear(input_size, 32)
self.activation = nn.ReLU()
self.output = nn.Linear(32, output_size)
def forward(self, x):
x = self.hidden(x)
x = self.activation(x)
return self.output(x)
C'est tout! Pytorch se charge du reste. Nous pouvons créer une instance de notre classe dans le fichier train.py. Ajoutons d'abord cet import au haut du ficher:
from mlp import MLP
On peut ensuite instancier notre modèle à la fin de notre fichier comme suit:
mlp = MLP(21, 4)
Nous avons presque tous les ingrédients pour commencer notre entraînement. Il reste à définir une fonction de perte. La fonction de perte permet de générer un signal d'erreur pour le modèle en lui laissant savoir à quel point sa prédiction est loin de la réponse attendu. Voyez ça comme un jeu de fléchettes : la cible représente la réponse correcte, et chaque lancer de fléchette représente une prédiction du modèle. La fonction de perte mesure à quel point la fléchette (la prédiction) s’éloigne du centre de la cible (la vérité). Si la fléchette tombe très loin, la perte est grande, ce qui indique au modèle qu’il doit s’améliorer. Si elle est proche du centre, la perte est petite, signifiant que le modèle a presque atteint la bonne réponse. Par exemple, dans un modèle qui prédit le prix d’une maison, si le modèle prédit 250 000 € alors que le prix réel est 300 000 €, la fonction de perte pourrait être simplement la différence absolue entre les deux, soit 50 000 €. C’est ce signal d’erreur que le modèle utilise pour ajuster ses paramètres et s’améliorer au fil des entraînements.
Le but du réseau de neurone est de minimiser la fonction de perte. Vous pouvez, très littéralement, imaginer le réseau de neurone comme un randonneur qui marche à travers une vallée, mais qui ne peut voir que 30cm devant lui dans toute les directions. Son objectif est de continuer à marcher dans la direction qui descend jusqu'à ce qu'il trouve le point le plus bas dans la vallée. Ce point est trouvé lorsqu'il n'existera plus de direction via laquelle il peut descendre encore davantage.
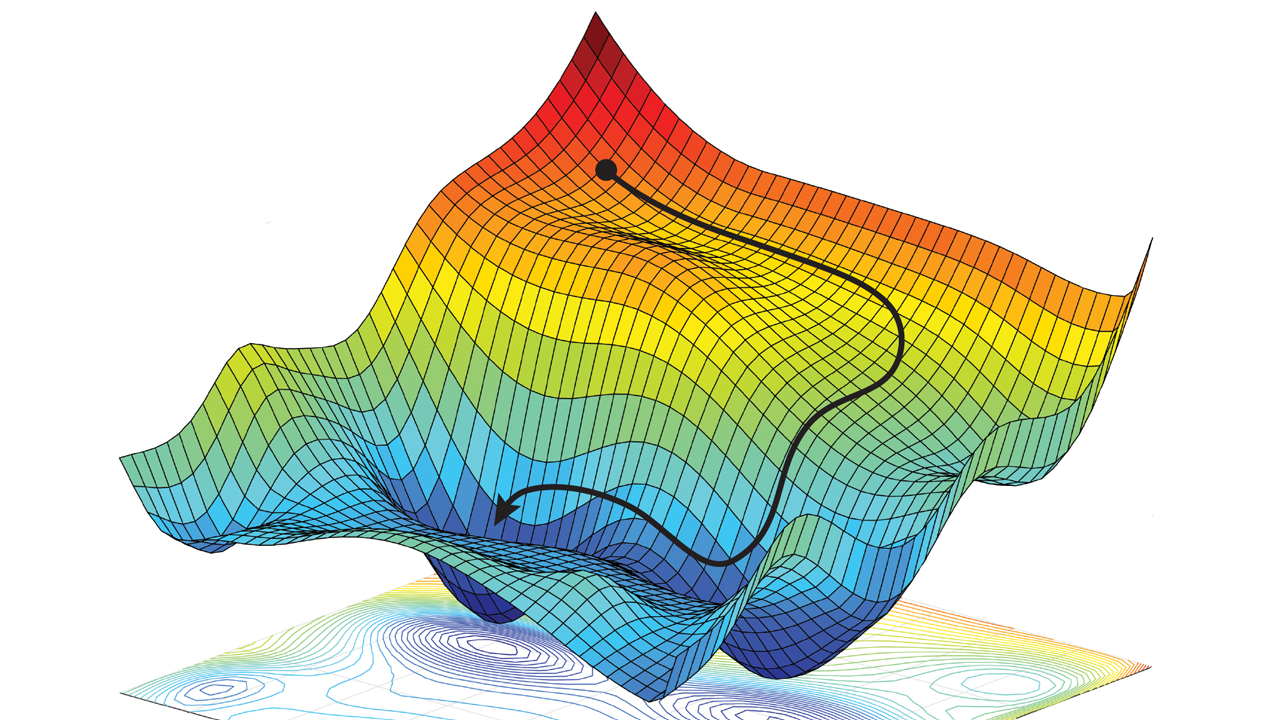
Dans notre cas, nous allons employé l'erreur d'entropie croisée. Je ne vais pas expliquer les mathématiques de cette fonction de perte, mais c'est une des plus simple et plus populaire en IA, alors je vous recommande de l'étudier. Ajoutez ceci après l'instanciation du modèle:
# Fonction de perte
criterion = nn.CrossEntropyLoss()
# Optimiseur avec pas de 0.01
optimizer = torch.optim.SGD(mlp.parameters(), lr=0.01)
L'optimiseur que nous allons utiliser pour commencer est le plus basique de tous et est connu sous le nom de descente de gradient. C'est le méchanisme qui nous permet de trouver la direction vers laquelle nous devons prendre un pas pour minimiser la fonction de perte. Écoutez ce vidéo avant de continuer pour comprendre le comportement d'un optimiseur et la différence entre SGD (le notre) et les plus efficaces comme Adam: vidéo.
Le pas, aussi connu sous le nom de learning rate est aussi une notion très importante en apprentissage machine avec descente de gradient. C'est la taille du pas que vous prenez lorsque vous descendez la fonction de perte. Imaginez une fourmie en train de traverser une vallée: ça prendra 1000 ans, et elle risque de penser qu'un tout petit trou est le fond de la vallée alors que ce n'est pas le cas! Imaginez maintenant un géant (très très géant): il passera assurement par dessus le minimum sans s'en rendre compte. Il faut trouver la taille de pas idéale pour atteindre le minimum dans un temps idéal.
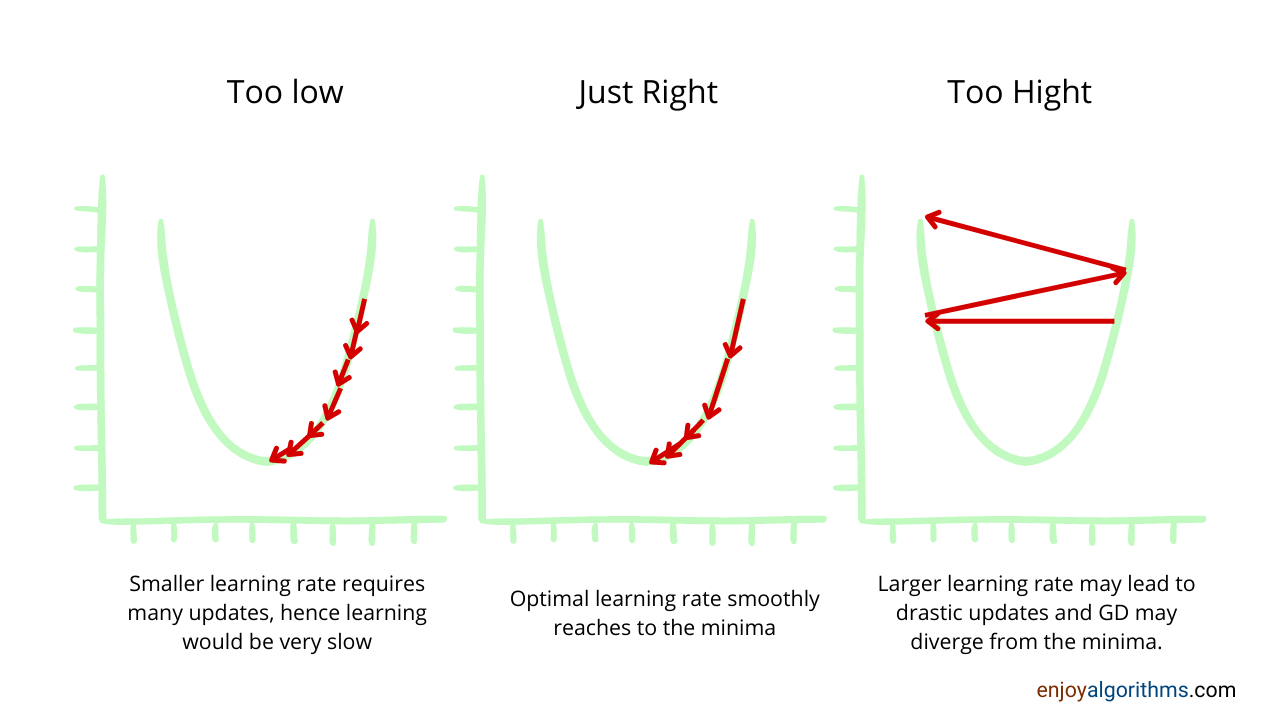
¶ 6. Entraîner le réseau de neurones
L'entraînement d'un réseau de neurones suit généralement les étapes suivantes :
-
Initialisation des paramètres – Les poids et biais du réseau sont initialisés, souvent de manière aléatoire ou à l'aide de méthodes spécifiques (cette étape est fait automatiquement par PyTorch).
-
Propagation avant (Forward Pass) – L'entrée est transmise à travers le réseau couche par couche, en appliquant les transformations linéaires et les fonctions d'activation, jusqu'à produire une prédiction en sortie.
-
Calcul de la perte – La différence entre la prédiction du modèle et la valeur attendue (vérité terrain) est mesurée à l'aide d'une fonction de perte (comme l'entropie croisée pour la classification ou l'erreur quadratique moyenne pour la régression).
-
Propagation arrière (Backward Pass) – L'algorithme de rétropropagation calcule le gradient de la perte par rapport aux poids du réseau en utilisant la différentiation automatique, permettant d’évaluer comment chaque paramètre influence l'erreur.
-
Mise à jour des poids – Un optimiseur (comme SGD, Adam ou RMSprop) ajuste les poids du réseau en fonction des gradients calculés afin de réduire l'erreur.
-
Répétition du processus – Ces étapes sont répétées sur de nombreux exemples du jeu de données, généralement en mini-lots (batchs), pendant plusieurs époques, jusqu'à ce que le modèle atteigne une performance satisfaisante. Dans notre cas, la tâche est assez facile et les requis de mémoire sont assez petit pour nous permettre de prendre tout l'ensemble de données dans une seule batch.
-
Évaluation sur l’ensemble de validation et de test – Une fois l’entraînement terminé, le modèle est testé sur des données qu’il n’a jamais vues pour s'assurer qu'il généralise bien et ne souffre pas d'overfitting.
Nous avons maintenant tous les ingrédients, il est temps de les assembler. Ajoutez ceci à la fin de votre code:
train_losses = []
val_losses = []
val_accuracies = []
# ~~~~~~~ Entraînement ~~~~~~~
# On voit l'ensemble de donnée 50 fois
EPOCHS=50
for epoch in range(EPOCHS):
mlp.train() # Modèle est mis en mode "train", ce qui active les gradients
outputs = mlp(X_train) # Passe la donnée à travers le modèle pour obtenir les prédictions
loss = criterion(outputs, y_train_oh) # Calcul la perte
optimizer.zero_grad() # Efface les gradients de l'ancienne rétropropagation
loss.backward() # Calcul les nouveaux gradients en fonction de la perte calculée
optimizer.step() # Mise à jour des poids du modèle en fonction des gradients
mlp.eval() # Modèle est mis en mode "eval", ce qui désactive les gradients
with torch.no_grad():
val_outputs = mlp(X_val) # Passe la donnée à travers le modèle pour obtenir les prédictions
val_loss = criterion(val_outputs, y_val_oh) # Calcul la perte
_, predicted = torch.max(val_outputs.data, 1) # On prend la classe avec la plus haute probabilité
_, true_labels = torch.max(y_val_oh.data, 1) # On prend la vraie classe (réponse)
val_accuracy = (predicted == true_labels).sum().item() / len(y_val_oh) # On calcul le nombre de fois que le modèle a raison
# Stockage des métriques
train_losses.append(loss.item())
val_losses.append(val_loss.item())
val_accuracies.append(val_accuracy)
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}, Val Accuracy: {val_accuracy:.4f}')
# Résultats finaux sur l'ensemble de validation
print("\nRésultats finaux sur l'ensemble de validation:")
print(f"Perte sur la validation: {val_losses[-1]:.4f}")
print(f"Précision sur la validation: {val_accuracies[-1]:.4f}")
# ~~~~~~~ Test ~~~~~~~
# Évaluation finale sur l'ensemble de test
mlp.eval()
with torch.no_grad():
test_outputs = mlp(X_test)
test_loss = criterion(test_outputs, y_test_oh)
_, predicted = torch.max(test_outputs.data, 1)
_, true_labels = torch.max(y_test_oh.data, 1)
test_accuracy = (predicted == true_labels).sum().item() / len(y_test_oh)
print("\nRésultats finaux sur l'ensemble de test:")
print(f"Perte sur le test: {test_loss.item():.4f}")
print(f"Précision sur le test: {test_accuracy:.4f}")
# ~~~~~~~ Visualisation ~~~~~~~
plt.figure(figsize=(12, 4))
# Graphique des pertes
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Perte en entrainement')
plt.plot(val_losses, label='Perte en validation')
plt.xlabel('Époque')
plt.ylabel('Perte')
plt.title('Pertes en entrainement et validation')
plt.legend()
# Graphique de la précision de validation
plt.subplot(1, 2, 2)
plt.plot(val_accuracies, label='Précision en validation')
plt.xlabel('Époque')
plt.ylabel('Précision')
plt.title('Précision en validation')
plt.legend()
plt.tight_layout()
plt.savefig('training_plot.png')
Ouf! Ça en fait beaucoup à absorber d'un coup! J'ai ajouté des commentaires à chaque ligne importante pour que vous puissez lire étape par étape.
Vous pouvez exécutez votre entraînement avec la commande suivante dans votre terminal:
python train.py
Le tout devrait se terminer très rapidement. À la fin de l'entraînement, votre terminal devrais afficher le résultat des pertes et des précisions. Additionellement, le code enregistre un graphique à la racine du projet avec la progression de la perte au fil des époques d'entraînement. Votre graphique devrait ressembler à quelque chose du genre:
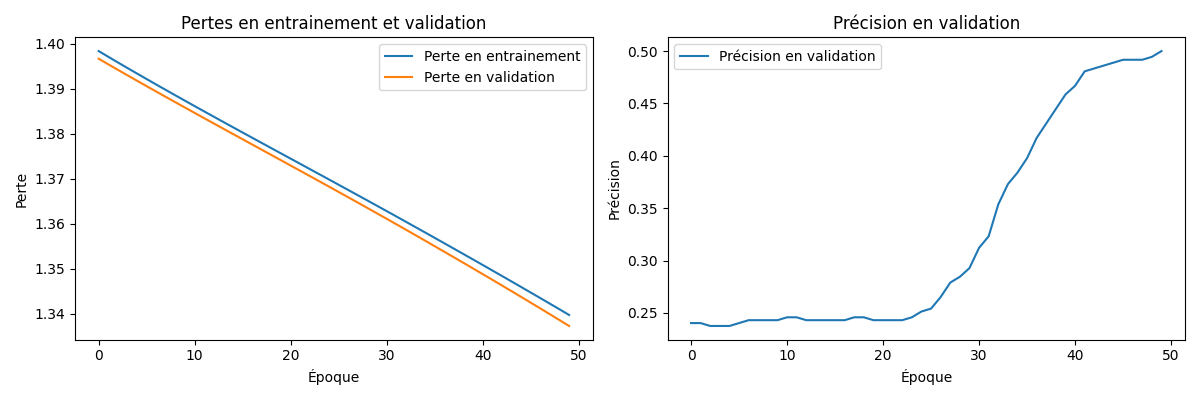
Avec les résultats suivants:
Résultats finaux sur l'ensemble de validation:
Perte sur la validation: 1.3291
Précision sur la validation: 0.5635
Résultats finaux sur l'ensemble de test:
Perte sur le test: 1.3338
Précision sur le test: 0.4975
La configuration actuelle obtient donc une précision de 56% sur l'ensemble de validation et 50% sur l'ensemble de test. Pas super... La bonne nouvelle est que nous ne rencontrons pas de problème de overfitting, puisque notre graphique montre que la perte de validation suit de près la perte d'entraînement et l'écart de précision entre la validation et le test n'est pas immense. Heureusement, il y a plusieurs choses que l'on peut faire pour essayer d'améliorer nos performances.
Expérimentez avec les 5 configurations suivantes et étudiez leur effet sur les performances du modèle (pas tous en même temps, sinon vous ne saurez pas qu'est-ce qui a contribué à quoi):
-
Nombre d'époche - laisser le modèle s'entraîner pendant plus ou moins longtemps
-
Taux d'apprentissage - un plus petit ou plus gros taux peut avoir un gros impact
-
Optimiseur - utilisez la documentation de PyTorch pour implémenter Adam au lieu de SGD (normalement ce n'est que remplacer une ligne de code)
-
Architecture du modèle - devrions nous ajouter plus de couches, ou peut-être employer des couches avec plus de neurones? Ou les deux?
-
Learning rate scheduler (AVANCÉ) - faites votre propre recherche pour implémenter un cosine annealing scheduler (pouvez vous expliquer son utilité?)
En jouant avec ces configurations, vous devriez être capable d'atteindre 99.75% sur l'ensemble de test. Attention, ce n'est pas toutes les configurations qui sont constructives! Une fois que vous avez réussi à obtenir un précision en dessus de 97~98% sur l'ensemble de test, amusez vous à revenir à l'arrière et à trouver la configuration la plus minimaliste possible tout en gardant des bonnes performances. Par exemple, quel est la taille du plus petit MLP capable de résoudre le problème? La réponse est tellement petite que ça peut mener à penser que le problème est probablement plus simplement résolu par une approche non-neuronale. Qu'en pensez-vous?
¶ Prochaines étapes?
Comme mentionné au début de ce document, les squelettes sont fournis par un modèle plus puissant. Dans le cas de notre projet, c'était un YOLOv8 fournit par la caméra ZED. Le problème avec cette solution, c'est que si le club décide de se défaire de la ZED, le mécanisme de "production" de squelettes sera perdu. Il existe cependant des alternatives open-source comme PoseNet et MoveNet. Un projet de grande envergure pour faire suite à ce tutoriel serait d'implémenter un système qui utilise un modèle de génération de squelettes open-source pour nourrir le réseau de neurones que vous venez de construire. Connectez ce système à une caméra pour avoir la détection de pose en temps réel!